Are We Reliable? — Product & Operational Maturity
Mini-Series: Reporting to the Board — What Every Tech Executive Should Measure (and Why)


Introduction
In Part 1, we looked at the foundation of every engineering organization — having the right team.
In Part 2, we explored how to get the best from them, by improving leverage, productivity, and developer experience.
And in Part 3, we focused on working on the right things, ensuring engineering effort aligns with company strategy.
Now we turn to the question that defines your team’s credibility; the one that shapes how the rest of the business perceives the engineering team:
Are we reliable?
Because no matter how talented, productive, or well-aligned your team is, if your product doesn’t hold up under pressure, nothing else matters. Reliability is the difference between promises and proof; it is what earns trust — from your board, your peers, your customers, and your own team.
At the board level, reliability hides behind questions like:
“Can we trust our SLAs and contracts?”
“Are we exposed to churn or reputational risk from outages?”
“Is our current speed putting stability at risk?”
When reliability cracks, everything downstream starts to shake: morale, reputation, and growth.
Are We Reliable?
Why it matters
Reliability is the foundation of trust between Engineering and the rest of the business.
Sales needs reliability to make credible commitments.
Customer success needs reliability to sleep at night.
Leadership needs reliability to plan with confidence.
If the product is unstable, it doesn’t matter how fast you ship or how impressive your roadmap is. Unreliability pushes teams into a reactive mode, where firefighting replaces innovation and urgency replaces strategy.
Signals / metrics to track
You don’t need every metric on this list. What matters is picking a reduced, coherent set that reflects your stage and your risk tolerance.
Some core signals:
Incidents —Frequency, impact, and mean time to recovery (MTTR). This is your first line of insight into real-world stability.
How often do things break?
How bad is it when they do?
How quickly do you recover?
Delivery quality — Change failure rate, rework ratio, or bug density can reveal whether speed is coming at the cost of quality.
How often do releases cause issues?
How much of your capacity is spent fixing what you already shipped?
Service health — Uptime, latency, and customer-facing SLAs/SLOs expose the gap between what’s promised and what’s delivered.
Are you meeting the commitments you made to customers?
Does performance degrade at peak usage?
Technical integrity — Debt trends, test coverage, and monitoring depth show whether risk is being contained or quietly accumulating.
Are you building on solid foundations or stacking risk?
How early can you detect issues?
Compliance & security — Certifications (SOC 2, ISO), audit readiness, vulnerability response time. These are compulsory in many industries.
Can you pass an audit without heroics?
How fast do you respond to security issues?
These are not just engineering metrics. They are risk indicators for the business.
How reliability evolves with maturity
Reliability typically evolves with the stage of the company growth.
1. Early stage: Scrappy
In a first stage, you rely on intuition and fast iteration. Incidents are acceptable if they unlock learning and speed. This stage is normally characterized by:
Minimal monitoring.
Few or no formal SLAs.
“Ship it and fix it live” is common behavior.
At this stage, you are intentionally trading stability for speed. That can be fine, as long as the trade-off is clearly known.
2. Scaling: Customers and contracts
As you grow, outages start to have a clear cost: churn, escalations, SLA penalties, and brand damage.
You introduce on-call rotations and basic incident management.
You start defining SLOs for critical flows.
You need clear incident communication to customers and internal stakeholders.
This is usually when leadership starts asking more precise questions about reliability and risk.
3. Accountable: Reliability is non-negotiable
When you operate in regulated or high-sensitivity environments (fintech, healthcare, enterprise, government), reliability becomes non-negotiable, and it must be measurable.
Compliance, audits, and contracts require evidence, not opinions.
You need to prove how your systems behave, not just claim they are “stable.”
Reliability becomes part of your positioning and sales narrative.
I always remember Facebook’s transition in their mission statement, from the early “move fast and break things” to “move fast with stable infrastructure” in 2014. The motto didn’t only change words; it reflected a new context and risk appetite.
The same applies to your organization: what is acceptable at seed stage is not acceptable when you’re processing millions of payments or health records.
Observability and AI-assisted reliability
At the accountable stage, observability and monitoring stop being “nice to have” tools and become part of your operational process.
You’re no longer asking:
“Did something break?”
You’re asking:
“How quickly do we see it, understand it, and learn from it?”
Modern APM and observability tools give you:
End-to-end visibility into performance and latency.
Clear traces when something goes wrong.
Patterns of failure across services and dependencies.
The rise of AI-assisted observability is already changing incident lifecycles:
Automatic anomaly detection and alerting.
Faster triage using correlation across logs, metrics, and traces.
Root-cause hints and even suggested mitigations.
We are still early, but the direction is clear: reliability will be increasingly augmented by AI, from detection to post-mortem learning.
From metrics to meaning
Numbers alone don’t make your organization reliable — behaviors do. A mature team doesn’t just fix incidents faster; it learns from them faster.
Some signs of that maturity:
Post-mortems as coaching tools: They are blameless, repeatable, and actually lead to changes in process and design.
Dashboards as decision allies: They are checked regularly, used in rituals (reviews, ops meetings), and drive concrete actions.
Shared understanding of risk: Engineers can explain not just what went wrong, but why it happened and what changed to avoid recurrences.
That’s when reliability becomes part of your culture, not just a KPI on a slide.
How Pensero helps Engineering Teams Build Reliability Into Their DNA
At Pensero, we go beyond traditional monitoring by connecting reliability signals directly to engineering contribution.
Our models can:
Detect when a code change introduces a defect.
Identify when a later change fixes that defect.
Attribute both to the right repositories, teams, and individuals.
This gives you a clear, data-backed view of the net reliability impact of your engineering activity:
Which parts of the codebase are most prone to rework due to incidents.
Which teams are consistently paying down quality issues vs. creating new ones.
How much effort is going into bug fixing and rework versus shipping new value.
In our Quality views, we surface:
Bug-fixing and rework effort over time, by team and repository.
Pull requests likely associated with introducing or fixing defects.
Trends that show whether your reliability profile is improving or degrading.
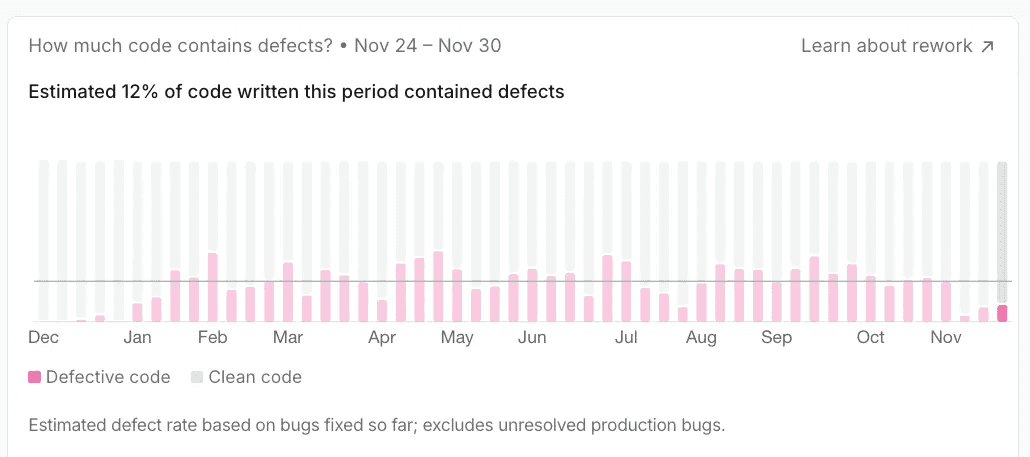
Pull Request with estimated inclusion of defective code in our Quality section
We also provide benchmarks across organizations, so you can calibrate whether your current balance of velocity and quality matches your risk appetite:
A fast-moving SaaS startup and a healthcare platform should not be held to the same tolerance.
What matters is that your operational behavior matches your principles and promises.
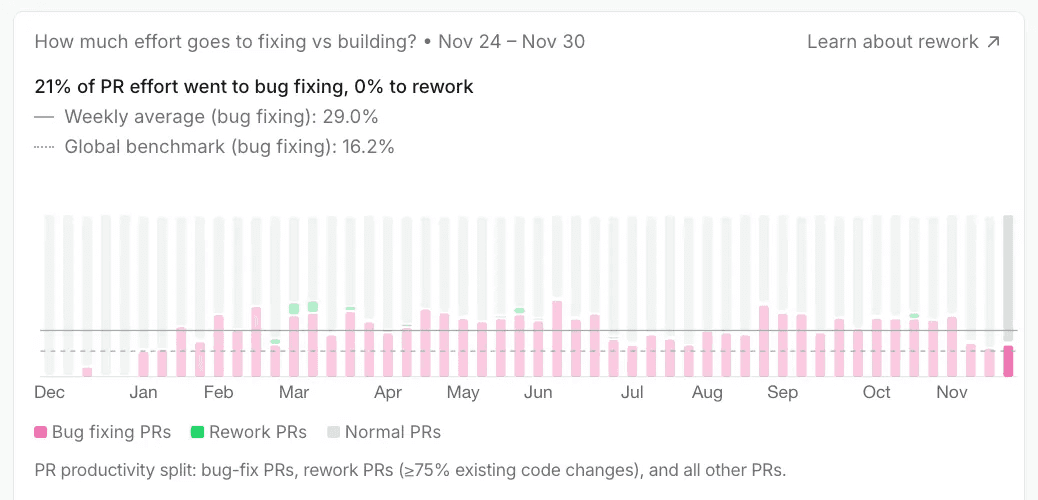
Bug fixing and Rework effort in our Quality section
Surfacing these reliability insights helps leadership ensure teams are not just shipping, but operating in harmony with the company’s risk profile and reliability standards.
Closing note
Reliability is more than uptime or SLA compliance, it’s the currency of trust.
It’s what allows your CEO to tell investors, “We’ve got this,” and know it’s true.
It’s what allows your team to move fast without being afraid of the next incident.
When reliability is visible, measurable, and embedded in how you operate, it stops being a question in a board meeting and starts being part of your identity.
What’s next
Once you know you’re reliable, there’s still one final question left, one that separates good teams from enduring ones:
Are we getting better over time?
In the final article of this series, we’ll talk about tracking improvement and trends:
How to measure progress, not perfection.
How to spot early signs of regression.
How to use data to tell a story of continuous growth to your board and your teams.
If you’ve ever tried to understand your team through data — and felt the frustration of doing it with spreadsheets, or with tools that only rely on ticket lifecycles or member surveys, without getting a holistic and factual view — stay tuned. We’re building something for you.
And if you want to join a blue-ocean opportunity — and help shape how engineering teams navigate this new technology age — check out our careers page.
